ML bias: guidelines to make ML models ethical and reduce risks of discrimination

This is a follow-up post from a first “ML bias: intro, risks and solutions to discriminatory predictive models”, a non-technical introduction to how predictive models impact our lives, the ways in which ML bias can “automate” inequality, and some general hints for avoiding bias in ML models.
Awareness of the potential for ML bias is a necessary first step for addressing it, but what comes next? In this second post, I’ll cover the main initiatives and frameworks, currently discussed in research and in industry, that Data Science teams can use to ensure the models we build are ethical and reduce the risk of bias and discrimination.
To be clear, technically there is no easy solution. Deleting a discriminatory variable (such as gender or ethnicity), for example, is not enough. This variable could be predicted from the rest of the variables available, or the bias might be coming from other sources independent to that variable. A comprehensive approach needs to have different strategies for both main components of any ML project: the dataset and the model.
Strategies to reduce the risk of bias from the datasets
The first thing we need to understand whenever we start a ML project is “What do I need to know about the data I am going to use?”. To answer this, currently the most well known framework is Datasheets for Datasets by Timnit Gebru et al., which proposes a standard for documenting datasets that aims to increase transparency, accountability, informed decisions, and awareness of potential biases the dataset might suffer from.
Datasheets for Datasets provides a list of questions that should be addressed when a dataset is created, ranging from motivation, composition, collection process, preprocessing, uses, distribution, and maintenance. In addition, each company, team, or project should adapt it further to suit their specific use case. It is a good practice to prepare this document for any dataset with the potential of being widely used, right after the Data Preparation or ETL phase of the project is finished, so that this information is available to any downstream models.

In the section of “uses”, some specific questions related to potential biases appear, but how can we know if we may be suffering from bias? To help navigate this topic, Harini Suresh and John Guttag from MIT, developed A Framework for Understanding Sources of Harm throughout the Machine Learning Life Cycle, which describes the importance of identifying sources of harm or bias of our data or model in order to be able to address them. In the article, sources of harm or bias are classified into 7 groups, 3 of them are related to the dataset: historical, representation and measurement bias.
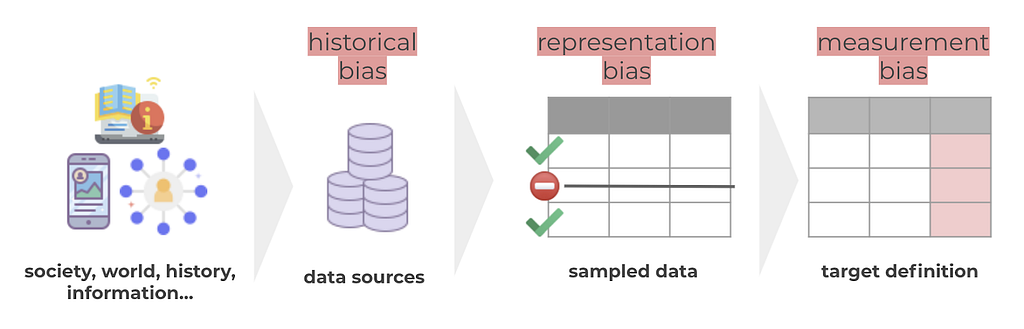
- Historical Bias: in this situation data reflects reality, but it is this reality that suffers from bias, discriminations, or stereotypes. Consider, for example, translations that assign a gender to words like nurse/clean/sad (she) vs. doctor/works/happy (he). This problem can be solved through over- or under-sampling. In the example mentioned above over sample texts where “she” is associated with words like doctor/works/happy.
- Representation Bias: in this situation our dataset misrepresents a segment of the overall population. An example of this would be the facial recognition models that struggle to detect the faces of women of color, simply because not as many samples of this segment appeared in the training data compared to other segments. This problem can be solved by adding more examples of the underrepresented class in the training dataset.
- Measurement Bias: typically, the target in our dataset is a proxy defined and codified to approximate a complex or abstract concept. Proxies become problematic when they don’t generalize well across groups. An example of this would be a model that determines the probability of a candidate being successful at university, and how “successful” is hard to codify and might mean different things for different segments of the population. For example, for people who need to work during university, “success” might imply different things than for people who can fully dedicate themselves to university, for instance, in terms of how long one needs to complete their studies. As you can imagine, in this case under/over sampling or adding more samples of the misrepresented class won’t help. To solve this problem, it is needed some work towards changes on how the target is defined to be more context aware.
Strategies to reduce the risk of bias from the model
To this point we have the dataset covered, and now come the next phases of the typical ML lifecycle: preprocessing, modeling, evaluation and deployment. It is in these phases when the dataset starts being used, and because of this, when the other 4 sources of harm appear: aggregation, learning, evaluation, and deployment bias.
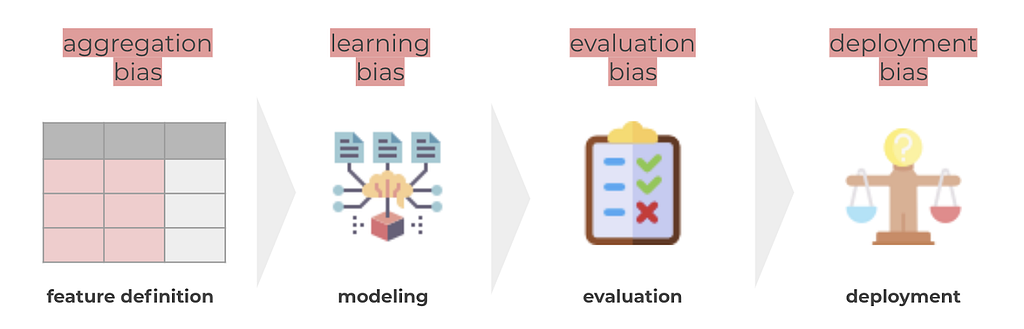
- Aggregation bias: in this situation, similarly to measurement bias, we have features that generalize too broadly when different meanings might be derived when looking at subgroups. As a simple example, think on how height is a feature that changes greatly by population segments.
- Learning bias: in this situation, model training produces different performance across different segments of the population. For example, there are proven examples where PCA brings a higher average reconstruction error for one group of the population than another (even when groups are similar in size). General solutions include modifying the cost function to positively discriminate against the minority classes, or adding constraints to the optimization problem to penalize unfairness.
- Evaluation bias: which happens when the evaluation dataset misrepresents certain segments of the population. If evaluation is biased, performance will seem to be good, and so the development team won’t notice the bad performance it has for the underrepresented groups, and the model won’t be challenged to improve in performance for those groups. An example of this is again the case of facial recognition models, where probably also the evaluation dataset had representation bias. This problem can be solved by balancing the dataset (in this case the evaluation data) adding more examples of the underrepresented groups.
- Deployment bias: which happens if the model is used for unintended purposes or situations that are not aligned with the data that the model was trained with. This is specially important for models that are used to take rather ethical predictions, such as models used to predict risk of teenage pregnancy, unemployment needs, woman abuse risk and many others, as can be found in this spanish news.
Because of these 4 sources, it is vital to be careful with any step or decision taken in the project, to reduce the risk of these and other types of bias. However, it is not only important how the data and modeling can derive into sources of bias, but also what are the initial intended situations where the model was expected to be used. To avoid unintended uses and provide further information and risks of the application of a given model, Model Cards for Model Reporting proposes to accompany each model with documentation. In it, one should be able to find performance characteristics of the model as well as advice on how to use it and potential biases and risks it might bring. The most relevant part in terms of bias is how this documentation asks for an evaluation of the model across different segments of the population, to ensure similar outcomes and error rates. This framework proposes to find the factors (population groups, environment or context…) where the algorithm might produce different results, and afterwards to provide results both in terms of unitary factors and intersection of results.

I’d like to put special attention to the part of intersectional factors, as usually the overlapping of identities (or belonging to multiple groups) makes bias or discrimination bigger. As an example, in the case of face recognition bias, it was women of color that suffered from bigger false positive rates, being at the intersection of woman AND person of color. In this post, there is an interesting discussion about this, and a final proposal of a simple check to measure: calculate the ratio between the subgroup with the lowest false positive rate and the highest false positive rate, the further this is from 1, the most it indicates the model can suffer from intersectional bias.
To fill in your Model Cards, you will mainly be needing model explainability frameworks that can easily be used in Python or R. Examples of such are:
- Feature importance: understanding what are the features that are more relevant to the model might make you realize the unintended or unexpected use of certain features by the model.
- Feature dependency: to understand better the marginalized effect of one or two variables into the target, all other features being equal.
- SHAP values: we might have features that are not important for the overall model but that are causing harm in the prediction of certain individuals, and SHAP values allow us to understand individual predictions based on each of the feature’s values.
- What-if scenarios: allow us to understand how the prediction would change for an individual if we changed some of the features. Ideally we should observe no changes due to intrinsic characteristics of the person.
- Evaluation of the model: we have mentioned how it is important to understand not only general performance of the model, but also performance for the different population segments we might have.
There are also specialized tools, providing as a service and with a nice UI the main analysis I was mentioning before, mostly from the main ML and data vendors.
ML bias in Glovo
In Glovo, the Data community and specially the Data Science Community, is conscious of the ethical implications of our models and the risks ML bias can bring. For this reason:
- We are providing training to our DS community about ML bias, how it can impact and why it is important to be aware and try to avoid it.
- We have added a “Bias & Ethics” section in the DS documentation, that allows us to raise any ethical issues or potential biases that could come from a project or an ML model. Note that this documentation is shared across the company with the goal to receive feedback from anyone interested in the project, which allows us to have many eyes and different perspectives into this topic.
- We are working towards becoming more transparent in terms of ML and ensuring that we champion AI ethics both internally and externally
Wrapping it up
Awareness of the potential risks predictive models can bring is the first step into trying to avoid them. Teams need to be aware of the possibilities of a model incurring bias, and know the risks derived from the given model or use of their data.
Complex problems like this one require complex (but feasible) solutions, that we can summarize as:
- Documenting the dataset (in terms of motivation, composition, collection process, preprocessing, uses, distribution and maintenance), to make sure any future use of the dataset will have all the context needed to make a right use.
- Understand and correct sources of bias (historical, representation, measurement, learning, aggregation, evaluation and deployment bias), with solutions ranging from context aware definition of the target or features, to over or under sampling the training and evaluation datasets.
- Documenting (and evaluating) the model, where one should be able to find performance characteristics of the model as well as advice on how to use it and potential biases and risks it might bring.
References:
[1] Datasheets for Datasets: https://arxiv.org/abs/1803.09010
[2] A Framework for Understanding Sources of Harm throughout the Machine Learning Life Cycle: https://arxiv.org/abs/1901.10002
[3] The Price of Fair PCA: One Extra Dimension: https://arxiv.org/abs/1811.00103
[4] Model Cards for Model Reporting: https://arxiv.org/abs/1810.03993
ML bias: guidelines to make ML models ethical and reduce risks of discrimination was originally published in Glovo Engineering on Medium, where people are continuing the conversation by highlighting and responding to this story.