Dramatically reducing CO2 emissions using incremental learning
Introduction: our training pipelines
Authors Adrià Salvador Palau Aleix López Pascual
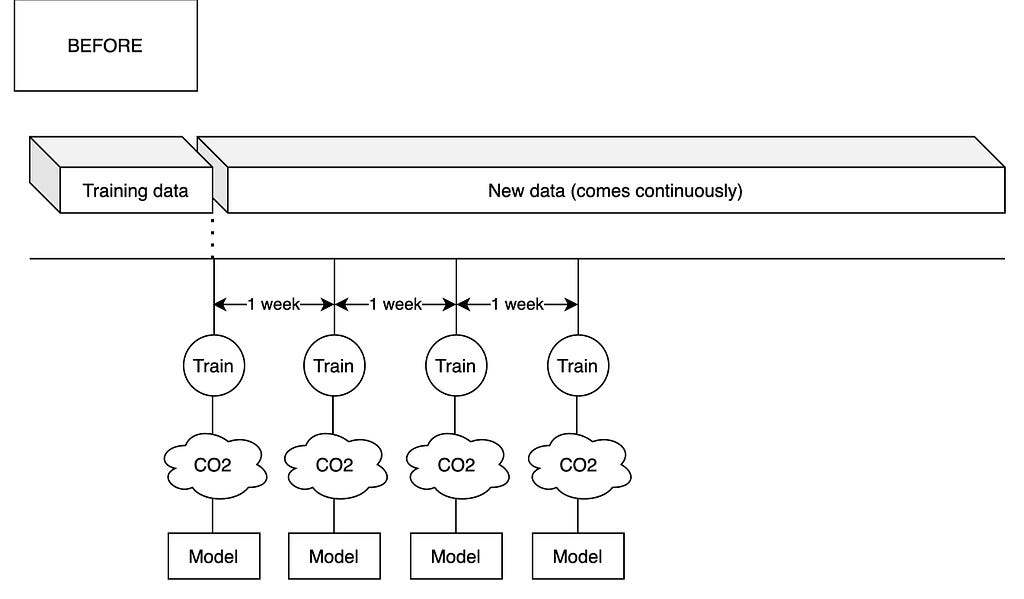
At Glovo we have tens of machine learning models that need to be trained continuously in order to adapt to our operations and to our ever-changing environment. This means that we currently perform weekly trainings of most of our machine learning models. These models are trained at city, country or global level and in doing so consume massive amounts of computational resources by provisioning large AWS EC2 instances over several days. These computer nodes are very energy intensive and therefore emit a significant amount of CO2 to the atmosphere.
For instance, we often use m5a.8xlarge EC2 machines to train our cities. M5a8xlarge is a machine with 32 CPUs and 128 GB of memory. Multiplied by tens of large cities, this is equivalent to having hundreds of high-performance laptops at full capacity dedicated solely to machine learning training. It is hard to estimate the exact amount of CO2 emitted but conservative estimates could put it up to the hundreds or even thousands of kilos every year.
Recently, at the CORE (R&D) team we performed a review of our training pipelines. In this review, we wanted to investigate if we could upgrade the way we trained our models in order to reduce the computational cost and environmental footprint of our machine learning pipelines. One of our ideas to reduce this was incremental learning.
You can see our current pipeline for training models below:
Incremental learning: what is it and what can it help with
To understand what incremental learning is, we must first understand what training a model means. In machine learning, training a model is akin to exploring a multidimensional geography until an optimum is found. In three dimensions, this is similar to the problem of finding a valley or a peak in a range of mountains. Here, the peak or valley represent variables that one wants to maximise or minimise (for example, the error of the machine learning model), and the directions where you can walk represent parameters of the model itself.
Following this analogy, incremental learning is akin to dropping a hiker (the model) already in the peak that it reached last time that he or she went for a hike. In this way the hiker does not need to hike all the way from the lowlands to the mountain range, saving tons of energy and work.
In more specific terms we implemented incremental learning by initialising our model in the state that we left it in our last training round. Then, we let our model “walk” a bit more by re-training the model with new data. Our hope was that this new data would be representative of recent changes in our operations while the initialised model contained all our historical knowledge.
At Glovo, we essentially have two types of models that are conducive to incremental learning strategies: neural networks and boosted trees. Incremental learning is performed very differently depending on which of the two is it: for neural networks, the same neural network can be used and incremental learning consists of refining its weights further with the new data. This means that model complexity remains constant and that there is no model weight penalty associated with the technique.
For boosted trees, however, the story is very different. Unlike neural networks, boosted trees are ensemble models: models that are composed by many smaller models (trees). Here, incremental learning means adding several new trees to the initial ensemble, with the hope that these trees will be able to learn the error introduced in the model by the changing dynamics of our logistics. This means that with boosted trees incremental learning comes with a penalty in terms of model size.
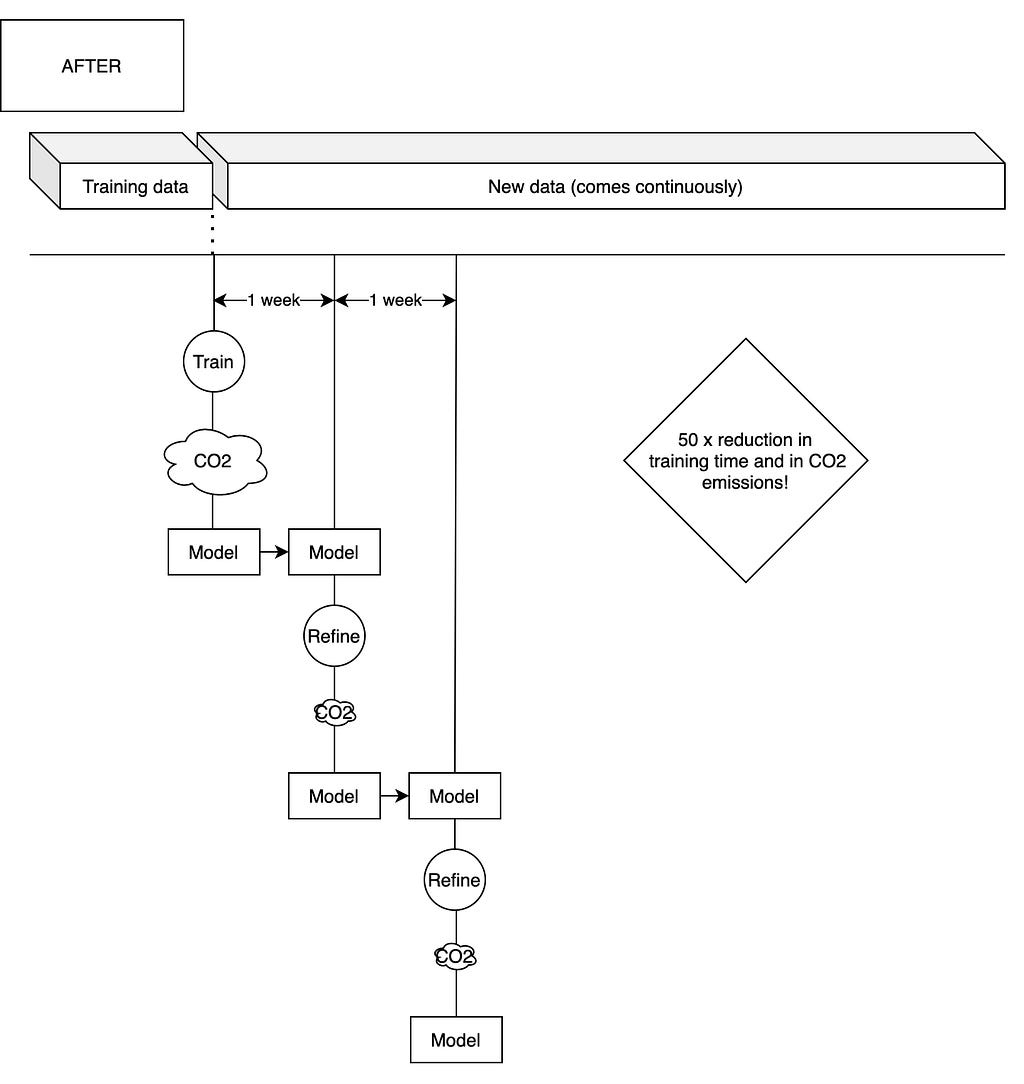
In the figure below you can see how we modified our training pipeline to feature incremental learning:
Results
After implementing incremental learning for our boosted tree regressors we saw incredibly promising results: training time reduced by a factor of 50. This corresponds to a similar decrease in associated emissions (there is a small correction to be considered, as there is some time needed to start the remote computer that trains our models and to process the data).
That decrease in training time and associated emissions, however, was not followed by an improvement in the accuracy of our models compared with retraining with all data. In fact, the overall model accuracy suffered a slight deterioration or remained flat (the maximum deterioration over 4 months of experiments was 0.9% over our main metric, which is an assumable decrease).
In addition to this, we realized that often the best strategy in terms of CO2 emissions and model accuracy was to not retrain the model at all. We noticed that in several cases the old model beat our retrained models both for incremental learning and training from scratch. For example, in our Waiting Time at Delivery model, the accuracy of a two-months old model was not statistically worse than when trained from scratch with new data!
This was a great surprise for us, as until then we trained our models periodically due to our past experience of model deterioration due to a phenomenon called “feature drift” — the situation where one of the features in the model significantly changes distribution over time, therefore deteriorating model quality.
Our plan moving forward
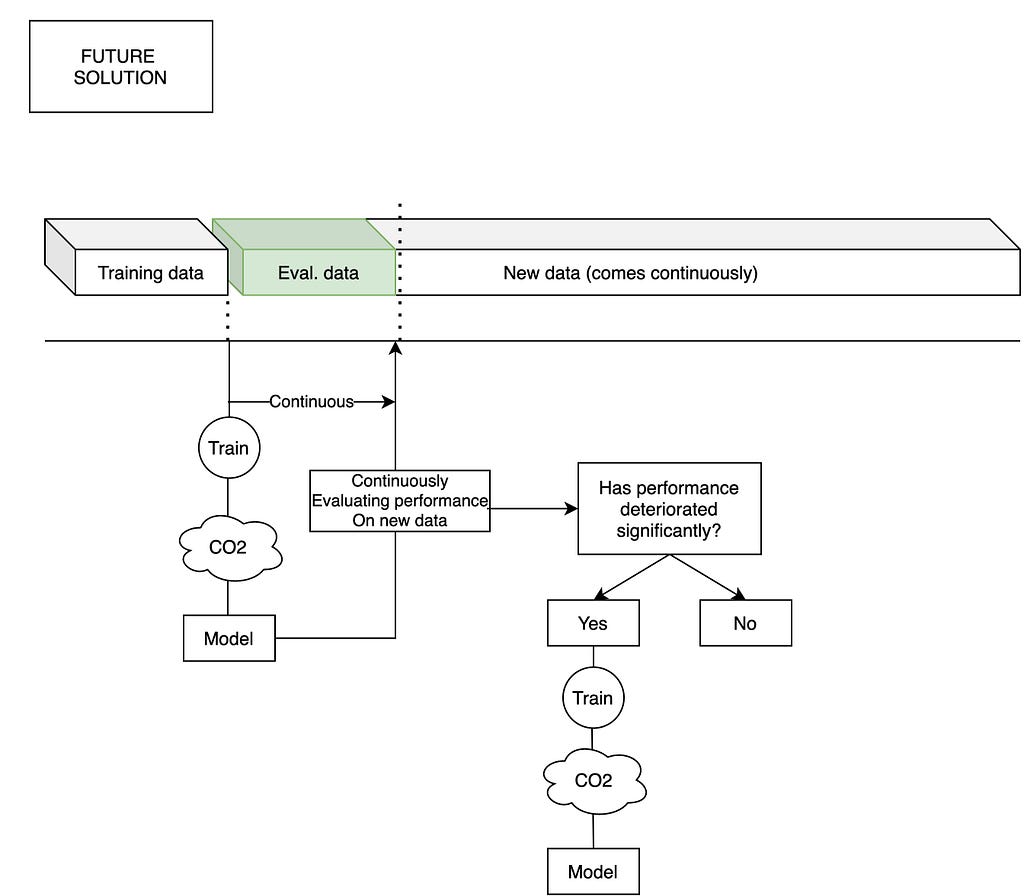
As follow up from these results, we are going to implement two pieces of technology that will dramatically reduce the CO2 emissions of our training pipelines.
First, we are on track to finish our real-time ML KPI module that allows us to measure the deterioration of model performance in real time, and therefore trigger model retrainings only when the model really needs to be retrained.
Second, we are implementing the possibility of conducting incremental learning instead of learning from scratch in the training pipelines offered by our machine learning platform. That is to say that when the model needs to be retrained, the training time will be greatly reduced.
Combined, these initiatives will reduce our emissions by a factor of 100, giving us a quantum leap in both training cost and environmental impact. As a company, we believe that the only way to fight the impending climate crisis is by radical changes like this.
In the figure below you can find our proposed “automated retraining” pipeline:
Dramatically reducing CO2 emissions using incremental learning was originally published in Glovo Engineering on Medium, where people are continuing the conversation by highlighting and responding to this story.